案例:TMDB-TOP300电影榜单分析
2026/4/16大约 5 分钟
需求分析
案例基于 TMDB 电影数据集,通过 Pandas 进行数据清洗与统计,并利用 Matplotlib 完成以下四个维度的可视化分析:
- 趋势分析:统计 TOP300 电影中,每一年上映电影数量的变化趋势(折线图)。
- 语言分布:统计并对比不同语言电影的数量分布(柱状图)。
- 类型偏好:统计并对比不同类型电影的数量占比(柱状图)。
- 评分构成:统计各个评分区间的电影比例(饼状图)。
1.准备工作
在开始分析之前,需要导入必要的依赖库、配置绘图环境、规划画布布局并加载原始数据。
1.1 导入依赖库
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.axes import Axes1.2 配置运行时参数
为了确保图表中的中文和负号能正常显示,需要预先设置 Matplotlib 的全局参数。
# 展示中文
plt.rcParams["font.sans-serif"] = ["SimHei"]1.3 创建子图布局
为了在一个画布上展示四个不同的图表,我们使用 plt.subplots(2, 2) 创建一个 2 行 2 列的网格布局。
# 创建 2x2 的子图画布
fig, axes = plt.subplots(2, 2, figsize=(20, 12), dpi=100)
# 添加画布标题
fig.suptitle("TMDB-TOP300电影榜单数据统计", fontsize=20, x=0.5, y=0.95)
# 调整子图间距,hspace:控制垂直间距,wspace:控制水平间距
fig.subplots_adjust(hspace=0.3, wspace=0.2)
# 获取子图
axes1: Axes = axes[0][0]
axes2: Axes = axes[0][1]
axes3: Axes = axes[1][0]
axes4: Axes = axes[1][1]1.4 加载数据
1.4.1 初步加载数据
首先尝试加载数据的前 30 行进行观察:
# 加载数据
data = pd.read_csv("data/movies.csv", nrows=30, usecols=["电影名", "年份", "上映时间", "类型", "时长", "评分", "语言"])
data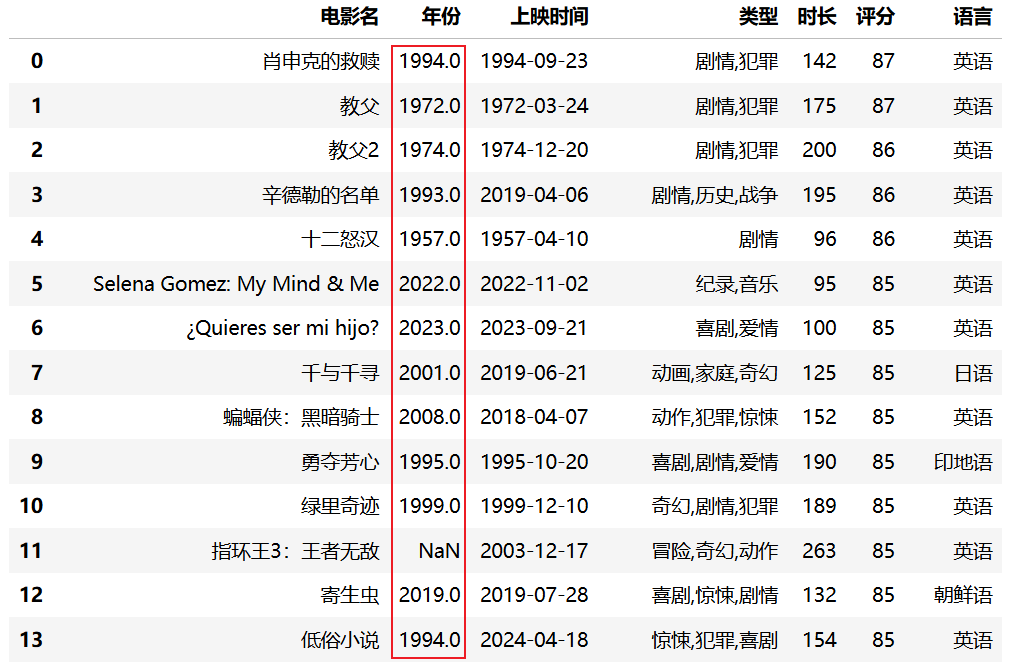
1.4.2 发现数据类型问题
观察输出结果,你会发现 年份 列的数据显示为 NaN 或者带有小数点(如 2023.0)。这是因为当 CSV 文件中某列存在缺失值时,Pandas 默认会将其转换为 float64 类型以兼容 NaN。
可以通过 dtypes 属性查看:
data.dtypes运行结果:
电影名 object
年份 float64 <-- 注意这里变成了浮点型
上映时间 object
类型 object
时长 int64
评分 int64
语言 object
dtype: object1.4.3 修正数据类型
为了保持年份为整数格式且支持缺失值,我们在读取数据时显式指定 年份 列的类型为 Int64(注意是大写的 I,这是 Pandas 特有的可空整数类型)。
# 重新加载数据,并指定“年份”列为可空整数类型
data = pd.read_csv("data/movies.csv", nrows=30, usecols=["电影名", "年份", "上映时间", "类型", "时长", "评分", "语言"],
dtype={"年份": "Int64"})
data运行结果:
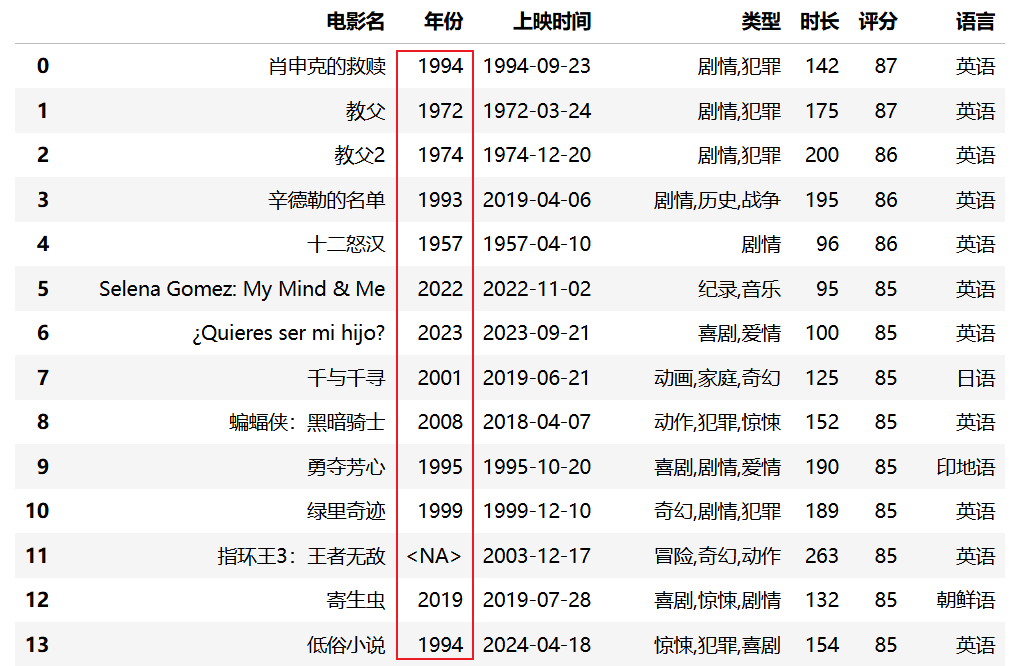
相关信息
int64:传统的 NumPy 整数类型,不支持缺失值(NaN)。Int64:Pandas 扩展整数类型,支持缺失值,显示时会保留整数格式而非浮点数。
2.绘制电影数量变化趋势折线图
2.1 处理缺失值
在原始数据中,部分电影的 年份 字段可能为空。观察数据可以发现,上映时间 字段(如 "2023-05-01")包含了年份信息。我们可以利用 Pandas 的字符串切片功能提取前四位,并将其填充到缺失的 年份 列中。具体方法可参考Pandas 数据清洗 - 填充缺失值。
data = pd.read_csv("data/movies.csv", usecols=["电影名", "年份", "上映时间", "类型", "时长", "评分", "语言"],
dtype={"年份": "Int64"})
# str[:4] 会提取类似 "2023-05-01" 中的 "2023"
data["年份"] = data["年份"].fillna(data["上映时间"].str[:4])
data.head(30)运行结果:
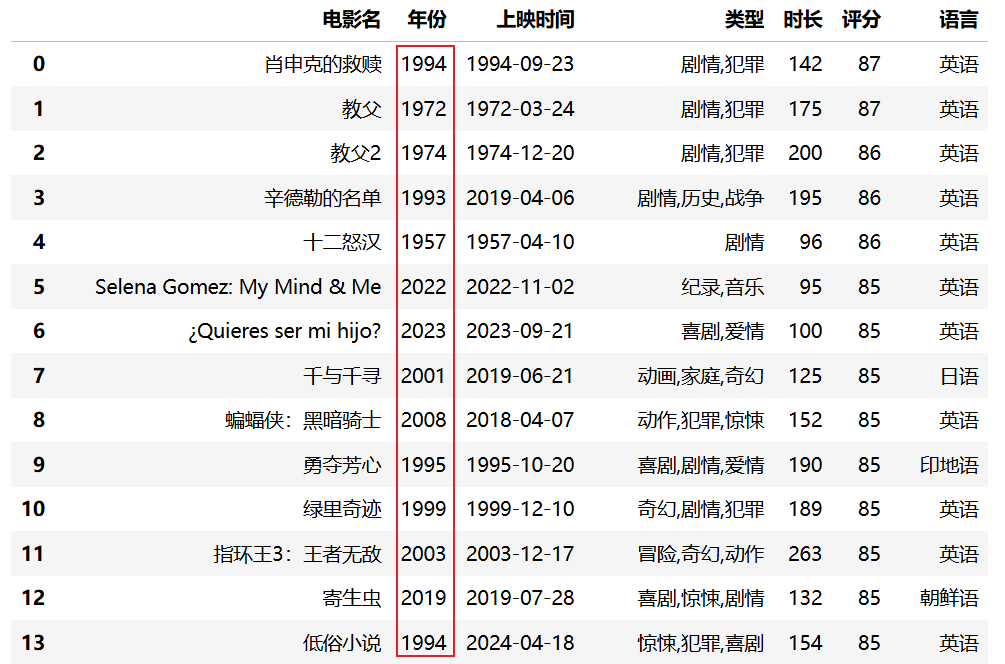
2.2 组装数据
# 1. 统计每年的电影数量
year_count = data.groupby("年份")["年份"].count()
# 2. 确定年份范围
min_year = year_count.index.min()
max_year = year_count.index.max()
# 3. 构建完整的 X 轴数据(从最小年份到最大年份的连续序列)
x = list(range(min_year, max_year + 1))
# 4. 构建对应的 Y 轴数据
# 使用 get(i, 0) 确保如果某年没有数据,则返回 0
y = [int(year_count.get(i, 0)) for i in x]2.3 绘制折线图
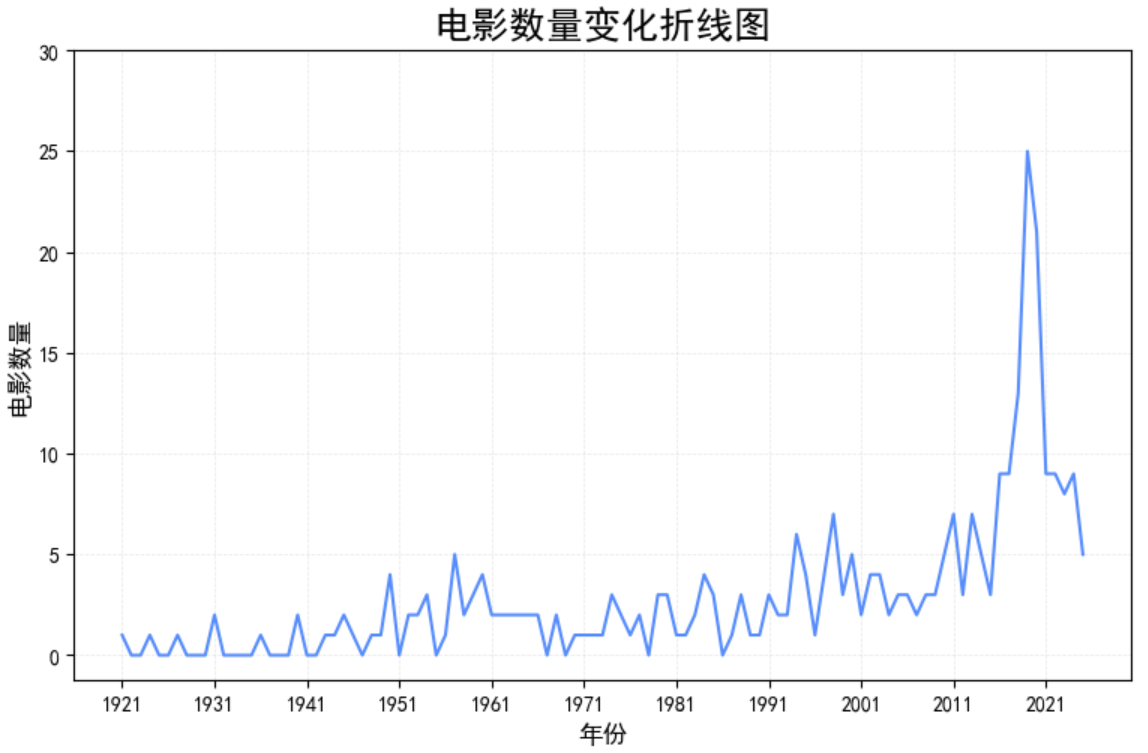
# 绘制折线
ax1.plot(x, y, color="green")
# 设置标题和坐标轴标签
ax1.set_title("年度电影产量变化趋势", fontsize=16)
ax1.set_xlabel("年份", fontsize=12)
ax1.set_ylabel("电影数量 (部)", fontsize=12)
# 每隔 10 年显示一个标签
ax1.set_xticks(x[::10])
# 动态计算步长
max_val = max(y)
step = 5
y_ticks = list(range(0, (max_val // step + 2) * step, step))
ax1.set_yticks(y_ticks)
# 添加网格线
ax1.grid(linestyle="--", alpha=0.3)运行结果:
3.绘制不同语言电影数量柱状图
# 1. 统计各语言电影数量并按降序排列
language_count = data.groupby("语言")["语言"].count().sort_values(ascending=False)
# 2. 提取 X 轴(语言名称)和 Y 轴(数量)数据
x_language = language_count.index.tolist()
y_language_count = language_count.values.tolist()
# 3. 在第二个子图 (ax2) 上绘制柱状图
ax2.bar(x_language, y_language_count, color="coral")
# 4. 设置标题、标签及刻度样式
ax2.set_title("不同语言电影数量分布", fontsize=16)
ax2.set_xlabel("语言", fontsize=12)
ax2.set_ylabel("电影数量 (部)", fontsize=12)
# 5. 旋转 X 轴标签,防止长文本重叠
ax2.tick_params(axis="x", rotation=45)
# 6. 添加网格线
ax2.grid(axis="y", linestyle="--", alpha=0.3)运行结果: