Pandas
1.Pandas 介绍
Pandas 是一个功能强大的结构化数据分析的工具集,底层是基于Numpy构建的,无论是在数据分析领域、还是大数据开发场景中都有显著的优势。
相关信息
Pandas 的核心数据结构包括:
- DataFrame:表格型数据结构,类似于 Excel 表格,包含行和列。
- Series:一维数组型数据结构,类似于 DataFrame 中的单独一列。
2.安装
在命令行中执行以下命令安装 Pandas:
pip install pandas==2.3.33.入门案例
基于 Pandas 统计班级学员的各科成绩的最高分、最低分、平均分。
- 在 Jupyter Notebook 文件中导入 pandas。此时可能会提示安装类型提示包(pandas-stubs),可根据个人需求选择是否安装。
import pandas as pd- 构造 DataFrame -- 创建数据集(学员成绩信息)
df = pd.DataFrame(
[{"姓名": "小王", "语文": 90, "数学": 80, "英语": 70}, {"姓名": "小张", "语文": 80, "数学": 90, "英语": 80},
{"姓名": "小李", "语文": 70, "数学": 80, "英语": 90}, {"姓名": "小赵", "语文": 80, "数学": 70, "英语": 90},
{"姓名": "小孙", "语文": 90, "数学": 80, "英语": 70}, {"姓名": "小钱", "语文": 80, "数学": 90, "英语": 80},
{"姓名": "小李", "语文": 70, "数学": 80, "英语": 90}, {"姓名": "小王", "语文": 80, "数学": 70, "英语": 90},
{"姓名": "小王", "语文": 90, "数学": 80, "英语": 70}, ])运行结果:
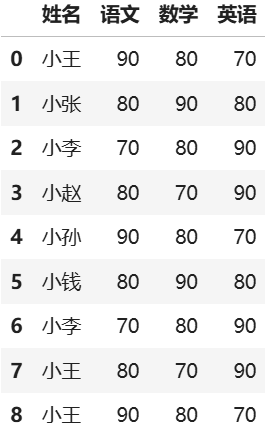
- 统计计算
print(f"语文最高分:{df["语文"].max()}, 最低分:{df["语文"].min()}, 平均分:{df["语文"].mean():.2f}")
print(f"数学最高分:{df["数学"].max()}, 最低分:{df["数学"].min()}, 平均分:{df["数学"].mean():.2f}")
print(f"英语最高分:{df["英语"].max()}, 最低分:{df["英语"].min()}, 平均分:{df["英语"].mean():.2f}")运行结果:
语文最高分:90, 最低分:70, 平均分:81.11
数学最高分:90, 最低分:70, 平均分:80.00
英语最高分:90, 最低分:70, 平均分:81.114.DataFrame
4.1 构建方式
构建 DataFrame 的方式有很多,以下是几种最常用的场景:
- 由字典列表构建(最常用,类似 JSON 格式):
- 由列字典构建(适合按列准备数据):
- 由元组列表构建(需指定
columns): - 由二维列表构建(需同时指定
columns和index):
df1 = pd.DataFrame([
{'姓名': '张三', '语文': 85, '数学': 92, '英语': 78},
{'姓名': '李四', '语文': 78, '数学': 88, '英语': 95},
{'姓名': '王五', '语文': 92, '数学': 96, '英语': 89}
])
df2 = pd.DataFrame({
'姓名': ['张三', '李四', '王五'],
'语文': [85, 78, 92],
'数学': [92, 88, 96],
'英语': [78, 95, 89]
})
df3 = pd.DataFrame([
('张三', 85, 92, 78),
('李四', 78, 88, 95),
('王五', 92, 96, 89)
], columns=['姓名', '语文', '数学', '英语'])
# 自定义索引为a,b,c
df4 = pd.DataFrame([
['张三', 85, 92, 78],
['李四', 78, 88, 95],
['王五', 92, 96, 89]
], columns=['姓名', '语文', '数学', '英语'], index=['a', 'b', 'c'])4.2 常见属性
4.2.1 索引
使用 index 属性获取 DataFrame 的行索引,再通过 to_list() 方法转换为列表。
df4.index.to_list()运行结果:
['a', 'b', 'c']4.2.2 列名
使用 columns 属性获取 DataFrame 的列名,再通过 tolist() 方法转换为列表。
df4.columns.to_list()运行结果:
['姓名', '语文', '数学', '英语']4.2.3 值
使用 values 属性获取 DataFrame 的所有数据值,再通过 tolist() 方法转换为嵌套列表。
df4.values.tolist()运行结果:
[['张三', 85, 92, 78], ['李四', 78, 88, 95], ['王五', 92, 96, 89]]4.2.4 元素个数
使用 size 属性获取 DataFrame 中元素的总个数(行数 × 列数)。
df4.size运行结果:
124.2.5 数据类型
使用 dtypes 属性获取每列的数据类型。需要注意的是,这里显示的是 NumPy 数据类型,而非 Python 原生数据类型。
df4.dtypes运行结果:
姓名 object
语文 int64
数学 int64
英语 int64
dtype: object相关信息
object通常对应 Python 的字符串类型int64是 64 位整数类型float64是 64 位浮点数类型(如果存在小数)
4.2.6 数据维度
使用 shape 属性获取 DataFrame 的数据维度,返回一个元组 (行数, 列数):
df4.shape运行结果:
(3, 4)5.Series
5.1 构建方式
s1 = pd.Series([10, 20, 30, 40, 50])
s2 = pd.Series((10, 20, 30, 40, 50), index=['a', 'b', 'c', 'd', 'e'])
s3 = pd.Series({'a': 10, 'b': 20, 'c': 30, 'd': 40, 'e': 50})
s4 = df1['语文']5.2 常见属性
5.2.1 索引
使用 index 属性获取 Series 的索引,并通过 tolist() 方法转换为列表。
s4.index.tolist()运行结果:
[0, 1, 2]5.2.2 值
使用 values 属性获取 Series 的所有数据值,并通过 tolist() 方法转换为列表。
s4.values.tolist()运行结果:
[85, 78, 92]5.2.3 元素个数
使用 size 属性获取 Series 中元素的总个数。
s4.size运行结果:
35.2.4 数据类型
使用 dtype 属性(注意是单数形式)获取 Series 的数据类型。与 DataFrame 不同,Series 只有一种数据类型。
s4.dtype运行结果:
dtype('int64')重要
Series 的 dtype 返回的是单个数据类型对象,而 DataFrame 的 dtypes 返回的是包含每列数据类型的 Series。
5.2.5 数据维度
使用 shape 属性获取 Series 的维度(行,)。由于 Series 是一维数据结构,因此返回的元组只有一个元素。
s4.shape运行结果:
(3,)相关信息
(3,) 表示这是一个包含 3 个元素的一维数组。注意元组中只有一个元素时需要加逗号。
6.数据读取与写入
Pandas 提供了丰富的 I/O 工具,支持多种数据格式的读取和写入,包括 CSV、Excel、JSON、SQL 等。
6.1 读取数据
Pandas 使用 read_xxx 系列函数读取数据,常用的有:
pd.read_csv():读取 CSV 文件pd.read_excel():读取 Excel 文件pd.read_json():读取 JSON 文件pd.read_sql():读取 SQL 数据库
import pandas as pd
# 读取 CSV 文件
df = pd.read_csv("data/sales.csv")
# 输出 DataFrame
df运行结果:
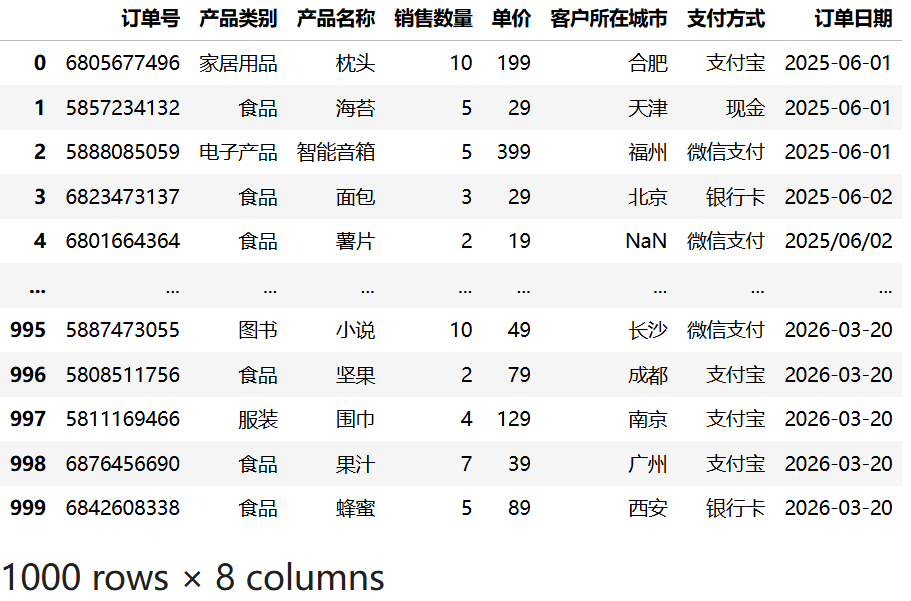
6.2 指定读取列
如果只需要读取部分列,可以使用 usecols 参数指定列名,这样可以减少内存占用并提高读取速度。
import pandas as pd
df = pd.read_csv("data/sales.csv", usecols=["订单号", "产品类别", "产品名称", "销售数量", "单价"])
df运行结果:
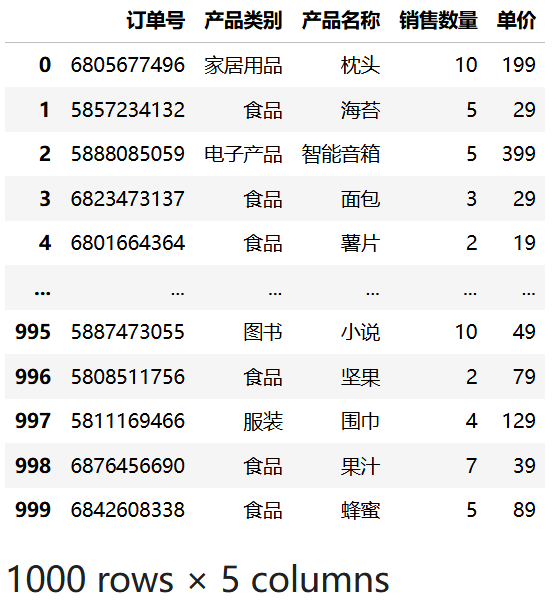
提示
usecols 参数也可以接受列索引列表,例如 usecols=[0, 1, 2] 表示读取前三列。
6.3 数据处理
读取数据后,可以进行各种数据处理操作。
import pandas as pd
df = pd.read_csv("data/sales.csv", usecols=["订单号", "产品类别", "产品名称", "销售数量", "单价"])
df["销售金额"] = df["销售数量"] * df["单价"]
df运行结果:
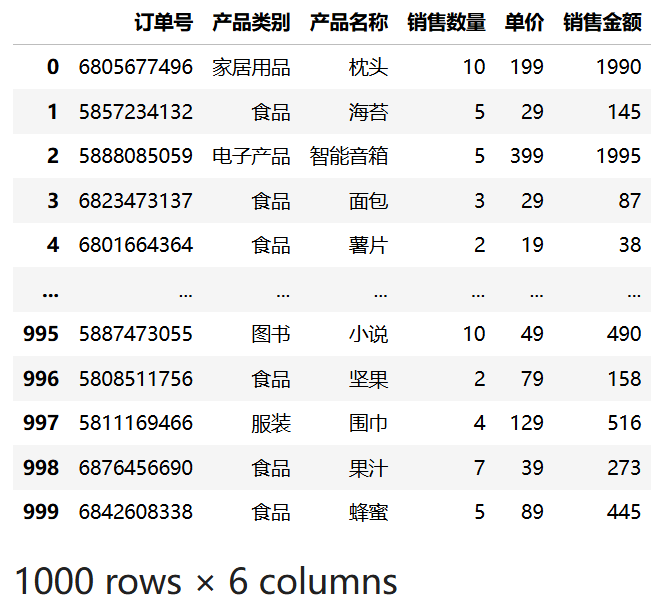
6.4 写入数据
Pandas 使用 to_xxx 系列方法将数据写入文件,常用的有:
df.to_csv():写入 CSV 文件df.to_excel():写入 Excel 文件df.to_json():写入 JSON 文件df.to_sql():写入 SQL 数据库
index=False:不写入索引列
import pandas as pd
df = pd.read_csv("data/sales.csv", usecols=["订单号", "产品类别", "产品名称", "销售数量", "单价"])
df["销售金额"] = df["销售数量"] * df["单价"]
df.to_csv("data/sales2.csv", index=False)常见参数说明
index=False:不写入行索引(默认会写入)encoding='utf-8-sig':指定编码格式,避免中文乱码sep=',':指定分隔符(CSV 默认为逗号)
7.数据查看、选择及过滤
7.1 数据查看
7.1.1 查看前 n 行数据
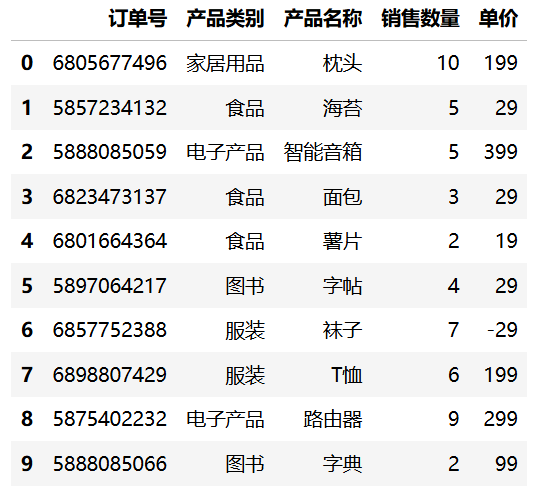
Pandas 提供了 head() 方法用于查看 DataFrame 的前几行数据,默认显示前 5 行。可以通过传入参数 n 来指定显示的行数,例如 head(10) 将显示前 10 行。
import pandas as pd
df1 = pd.read_csv("data/sales.csv", usecols=["订单号", "产品类别", "产品名称", "销售数量", "单价"])
df1.head(10)运行结果:
7.1.2 查看最后 n 行数据
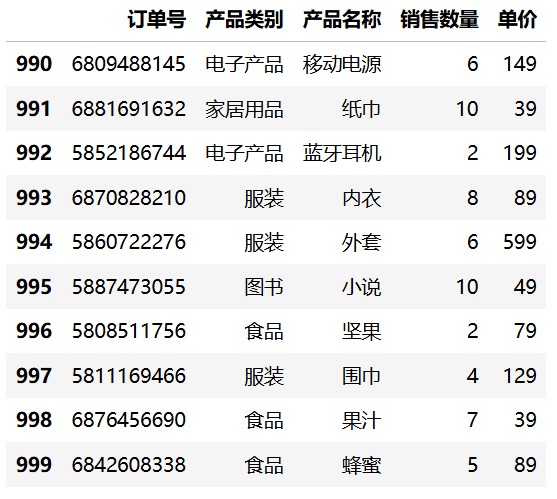
Pandas 提供了 tail() 方法用于查看 DataFrame 的最后几行数据,默认显示最后 5 行。可以通过传入参数 n 来指定显示的行数,例如 tail(10) 将显示最后 10 行。
import pandas as pd
df1 = pd.read_csv("data/sales.csv", usecols=["订单号", "产品类别", "产品名称", "销售数量", "单价"])
df1.tail(10)运行结果:
7.1.3 查看数据统计信息
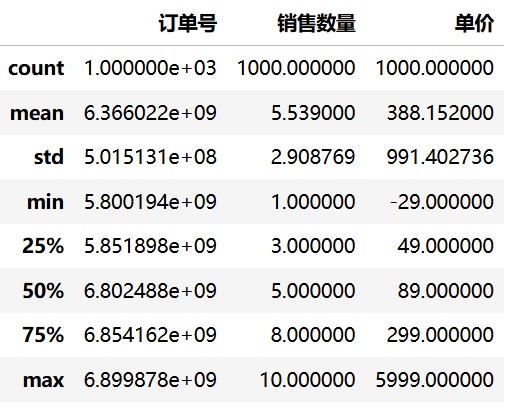
使用 describe() 方法可以快速查看 DataFrame 中数值型列的统计摘要信息,包括计数、均值、标准差、最小值、四分位数和最大值等常用统计指标。
import pandas as pd
df1 = pd.read_csv("data/sales.csv", usecols=["订单号", "产品类别", "产品名称", "销售数量", "单价"])
df1.describe()运行结果:
7.1.4 查看数据信息
使用 info() 方法可以查看 DataFrame 的基本信息,包括每列的列名、非空值数量、数据类型和内存占用等。
import pandas as pd
df1 = pd.read_csv("data/sales.csv", usecols=["订单号", "产品类别", "产品名称", "销售数量", "单价"])
df1.info()运行结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 订单号 1000 non-null int64
1 产品类别 1000 non-null object
2 产品名称 1000 non-null object
3 销售数量 1000 non-null int64
4 单价 1000 non-null int64
dtypes: int64(3), object(2)
memory usage: 39.2+ KB7.2 数据选择
7.2.1 选择单列
使用方括号 [] 加上列名可以选择单个列,返回一个 Series 对象。
import pandas as pd
df2 = pd.read_csv("data/sales.csv", usecols=["订单号", "产品类别", "产品名称", "销售数量", "单价"])
df2["产品名称"]运行结果:
0 枕头
1 海苔
2 智能音箱
3 面包
4 薯片
...
995 小说
996 坚果
997 围巾
998 果汁
999 蜂蜜
Name: 产品名称, Length: 1000, dtype: object相关信息
返回结果是 Series 类型,包含索引、值和元数据信息。
7.2.2 选择多列
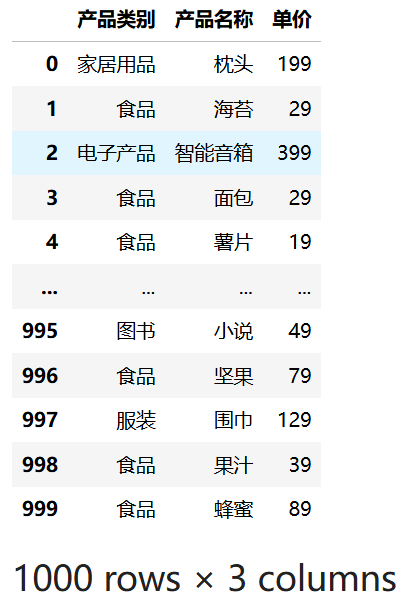
使用双层方括号 [[]] 传入列名列表可以选择多个列,返回一个新的 DataFrame。
import pandas as pd
df2 = pd.read_csv("data/sales.csv", usecols=["订单号", "产品类别", "产品名称", "销售数量", "单价"])
df2[["产品类别", "产品名称", "单价"]]运行结果:
重要
必须使用双层方括号,单层方括号只能选择单列或进行条件筛选。
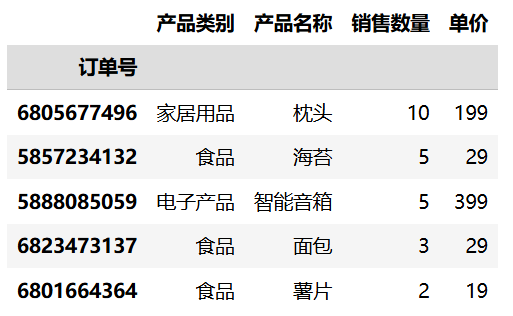
7.2.3 基于行号选择行
使用 iloc 属性可以通过行号来选择行,语法如下:
df.iloc[start:stop:step]参数说明:
start:起始位置(包含),默认为 0stop:结束位置(不包含)step:步长,默认为 1
import pandas as pd
df2 = pd.read_csv("data/sales.csv", usecols=["订单号", "产品类别", "产品名称", "销售数量", "单价"], index_col="订单号")
df2.iloc[0:5:1]运行结果:
重要
行号与索引是两个不同的概念。
- 行号(iloc):基于位置的整数索引,从 0 开始计数,类似于列表的下标
- 索引(loc):基于标签的索引,可以是整数、字符串或其他类型,是 DataFrame/Series 的实际索引值
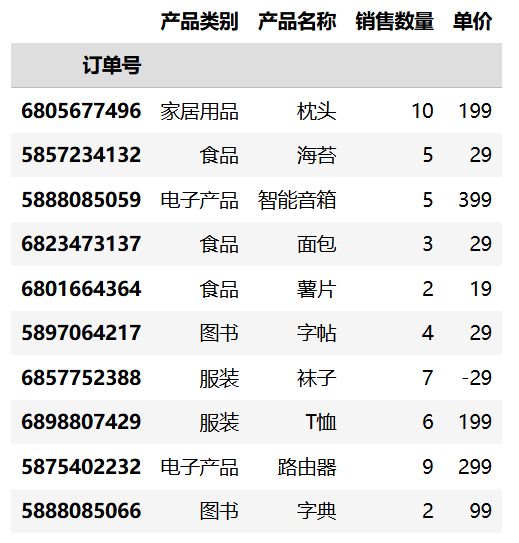
7.2.4 基于索引选择行
使用 loc 属性可以通过标签索引来选择行,语法如下:
df.loc[start:stop:step]参数说明:
start:起始位置(包含),默认为第一个索引stop:结束位置(包含),这是与iloc的主要区别step:步长,默认为 1
注意
与 iloc 不同,loc 的切片范围是两端都包含的(即 stop 对应的行也会被选中)。此外,start 和 stop 使用的是实际的索引标签值,而非位置编号。
import pandas as pd
df2 = pd.read_csv("data/sales.csv", usecols=["订单号", "产品类别", "产品名称", "销售数量", "单价"], index_col="订单号")
df2.loc[6805677496:5888085066:1]运行结果:
7.3 数据过滤
Pandas 提供了强大的数据过滤功能,可以通过布尔索引、条件表达式等方式筛选出符合条件的数据。
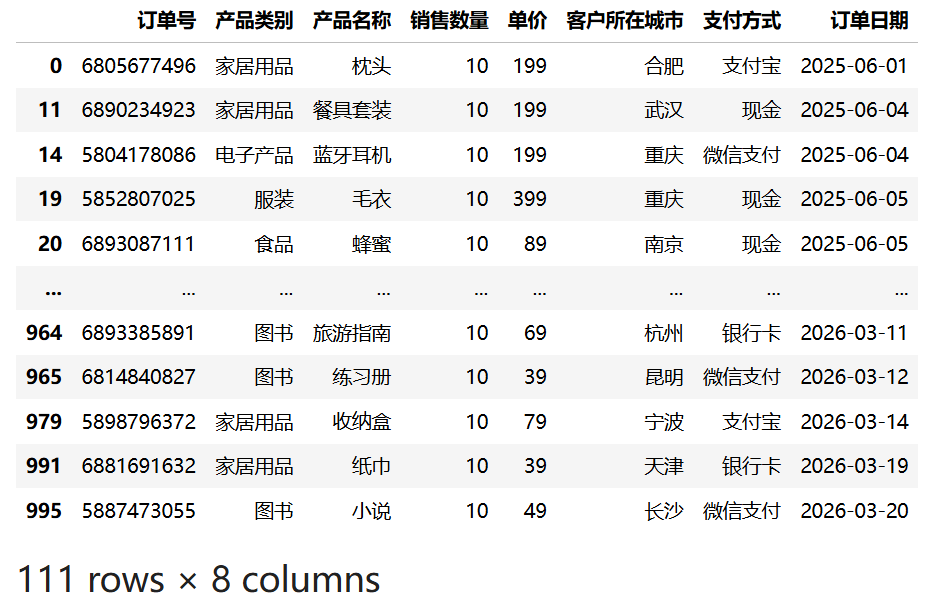
7.3.1 单条件筛选
使用比较运算符可以进行单条件筛选。以下示例筛选出"销售数量"大于等于 10 的所有记录:
import pandas as pd
df3 = pd.read_csv("data/sales.csv")
df3[df3["销售数量"] >= 10]运行结果:
相关信息
df3["销售数量"] >= 10 生成一个布尔 Series,Pandas 根据布尔值筛选出为 True 的行。
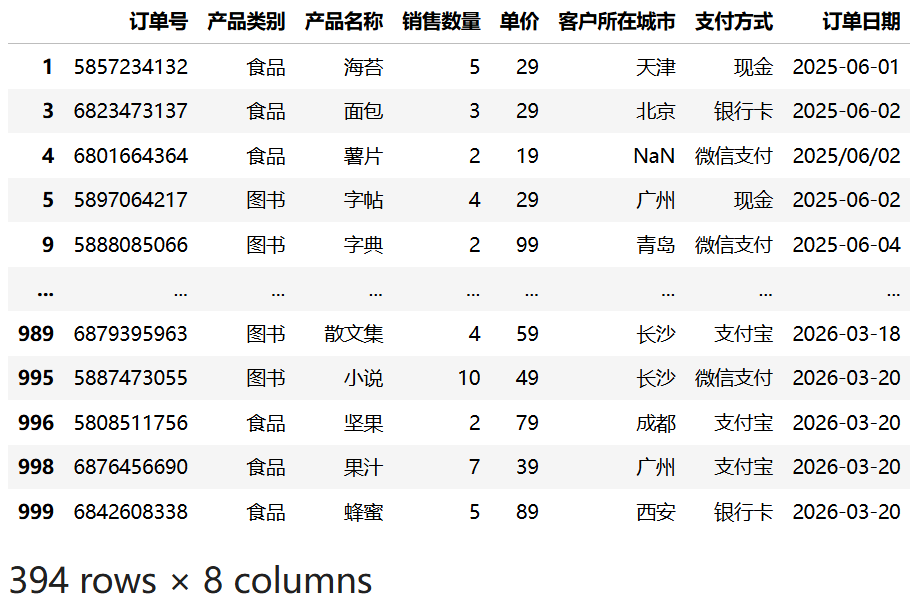
7.3.2 多值匹配筛选
使用 isin() 方法可以筛选某列的值在指定列表中的记录。以下示例筛选出"产品类别"为"食品"或"图书"的记录:
import pandas as pd
df3 = pd.read_csv("data/sales.csv")
df3[df3["产品类别"].isin(["食品", "图书"])]运行结果:
提示
isin() 方法等价于 SQL 中的 IN 操作符,适合处理多个离散值的匹配。
7.3.3 范围筛选
使用 between() 方法可以筛选某列的值在指定范围内的记录。以下示例筛选出"单价"在 100 到 200 之间(包含边界)的记录:
import pandas as pd
df3 = pd.read_csv("data/sales.csv")
df3[df3["单价"].between(100, 200, inclusive="both")]运行结果:
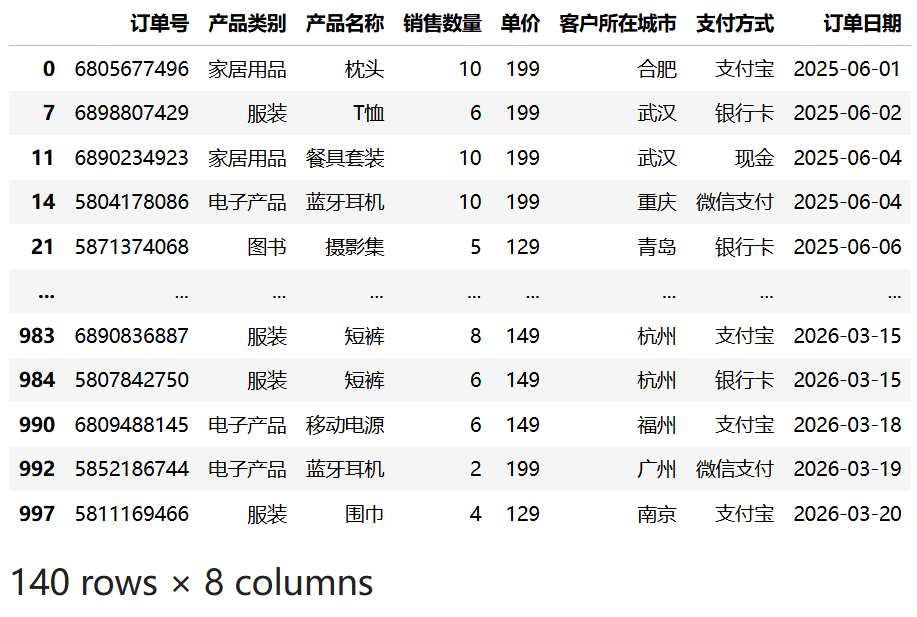
参数说明
inclusive="both":包含上下边界(默认值)inclusive="neither":不包含上下边界inclusive="left":只包含左边界inclusive="right":只包含右边界
7.3.4 多条件组合筛选(AND)
使用 & 运算符可以组合多个条件,实现"与"逻辑。以下示例筛选出"销售数量"大于等于 8 且 "单价"大于等于 100 的记录:
import pandas as pd
df3 = pd.read_csv("data/sales.csv")
df3[(df3["销售数量"] >= 8) & (df3["单价"] >= 100)]运行结果:
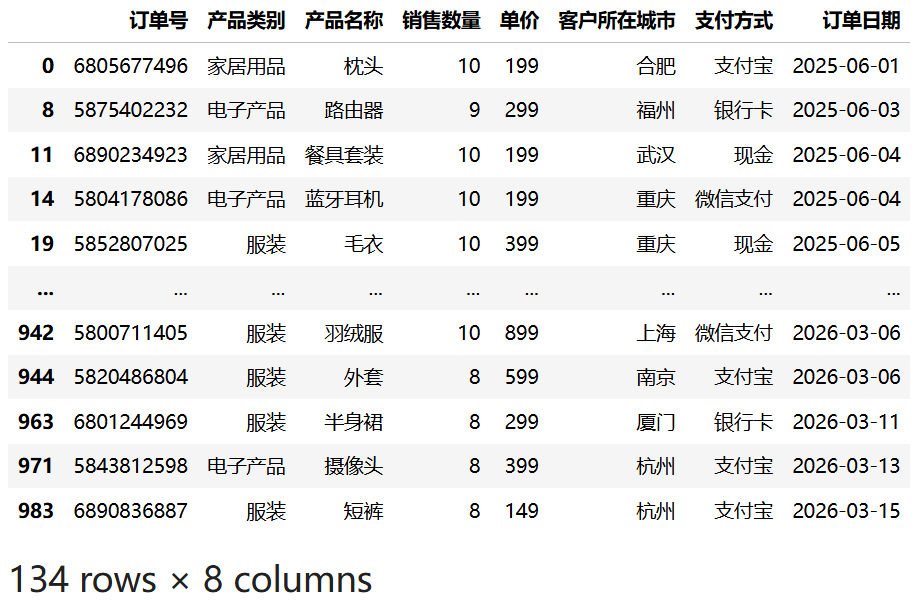
重要
- 每个条件必须用括号
()包裹,否则会因为运算符优先级导致错误 - 使用
&表示"与"(AND),使用|表示"或"(OR) - 不能使用 Python 的
and和or关键字
7.3.5 复杂多条件组合筛选
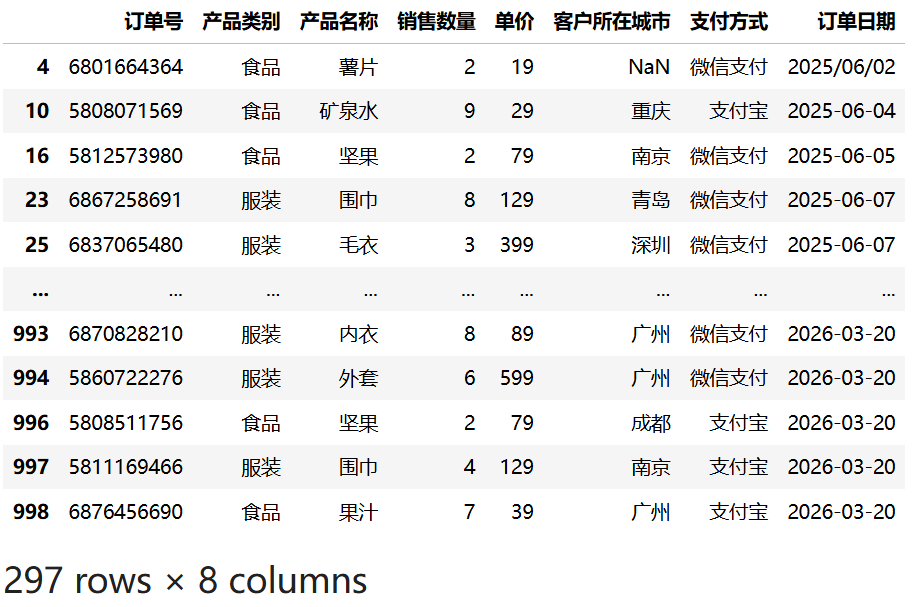
可以组合多个条件实现更复杂的筛选逻辑。以下示例筛选出"产品类别"为"服装"或"食品",且 "支付方式"为"支付宝"或"微信支付"的记录:
import pandas as pd
df3 = pd.read_csv("data/sales.csv")
df3[
(df3["产品类别"].isin(["服装", "食品"]))
& (df3["支付方式"].isin(["支付宝", "微信支付"]))
]运行结果:
8.数据清洗
数据清洗是指发现并纠正数据中可识别的错误的过程,包括处理缺失值、重复值、异常值,统一数据格式,保证数据的一致性。
8.1 缺失值处理
缺失值(NaN/None)是数据清洗中常见的问题,Pandas 提供了完善的方法来检测和处理缺失值。
8.1.1 查看缺失值
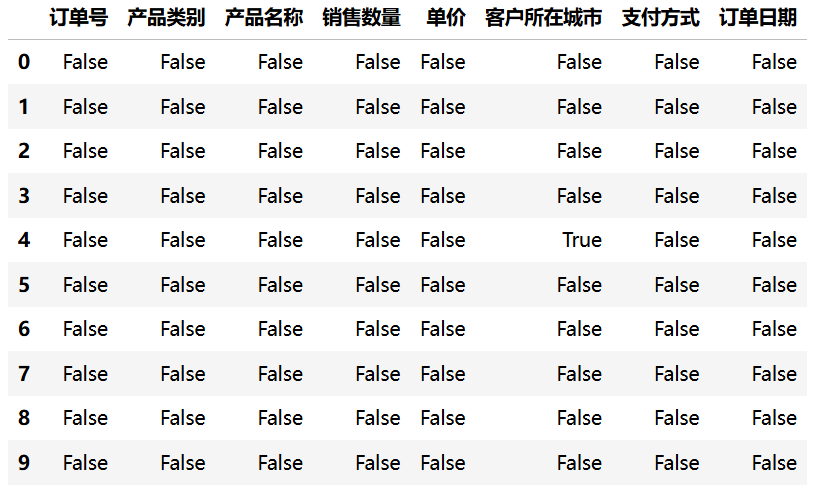
使用 isnull() 方法可以检测 DataFrame 中的缺失值,返回一个布尔型 DataFrame,其中缺失值标记为 True,非缺失值标记为 False。
import pandas as pd
df = pd.read_csv("data/sales.csv")
df = df.head(10)
df.isnull()运行结果:
提示
也可以使用 notnull() 方法,它与 isnull() 相反,非缺失值标记为 True,缺失值标记为 False。
8.1.2 删除缺失值
使用 dropna() 方法可以删除包含缺失值的行或列。
常用参数
axis=0:删除包含缺失值的行(默认)axis=1:删除包含缺失值的列how='any':只要有缺失值就删除(默认)how='all':所有值都是缺失值才删除subset=['列名']:只检查指定列的缺失值thresh=n:至少有 n 个非缺失值才保留
import pandas as pd
df = pd.read_csv("data/sales.csv")
df = df.head(10)
df.isnull()
# 删除缺失值所在行
df_row_dropped = df.dropna()
# 删除缺失值所在列
df_col_dropped = df.dropna(axis=1)
df_col_dropped运行结果(删除缺失行):
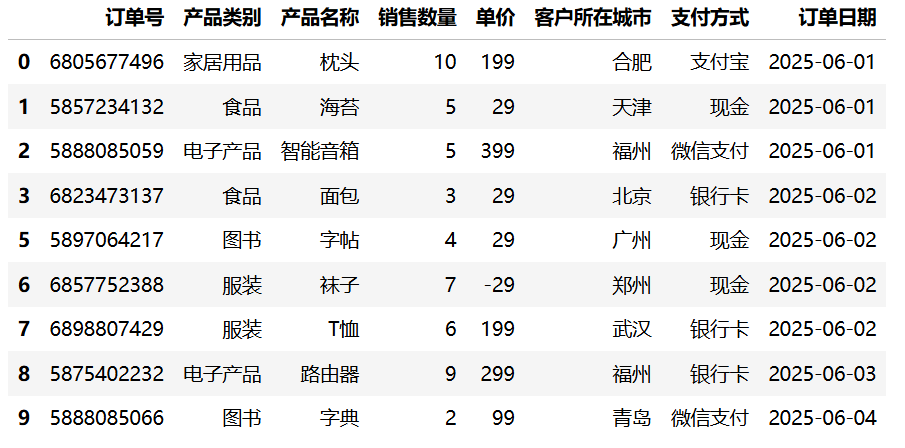
运行结果(删除缺失列):

8.1.3 填充缺失值
使用 fillna() 方法可以用指定的值或策略填充缺失值,而不是直接删除它们。这在保留数据完整性时非常有用。
常用参数
value:用于填充的值(可以是标量、字典、Series 或 DataFrame)method:填充方法,'ffill'(向前填充)或'bfill'(向后填充)axis:填充的轴,0 为行,1 为列limit:限制连续填充的最大数量inplace:是否原地修改,默认为False
1. 填充指定值
可以使用固定的值(如 0、均值、中位数或特定字符串)填充所有缺失值。
import pandas as pd
df = pd.read_csv("data/sales.csv")
df = df.head(10)
df.fillna("---")运行结果:
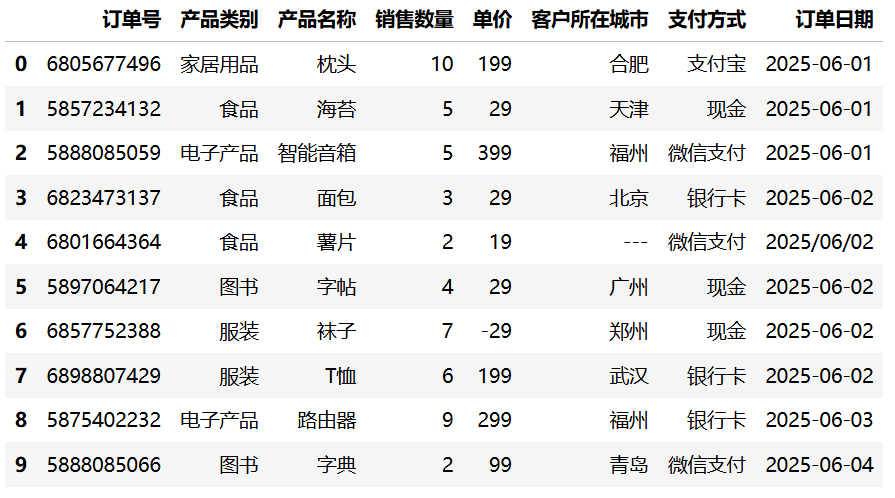
2. 向前填充(ffill)
使用前一个非缺失值填充当前的缺失值,常用于时间序列数据。
import pandas as pd
df = pd.read_csv("data/sales.csv")
df = df.head(10)
df.ffill()运行结果:
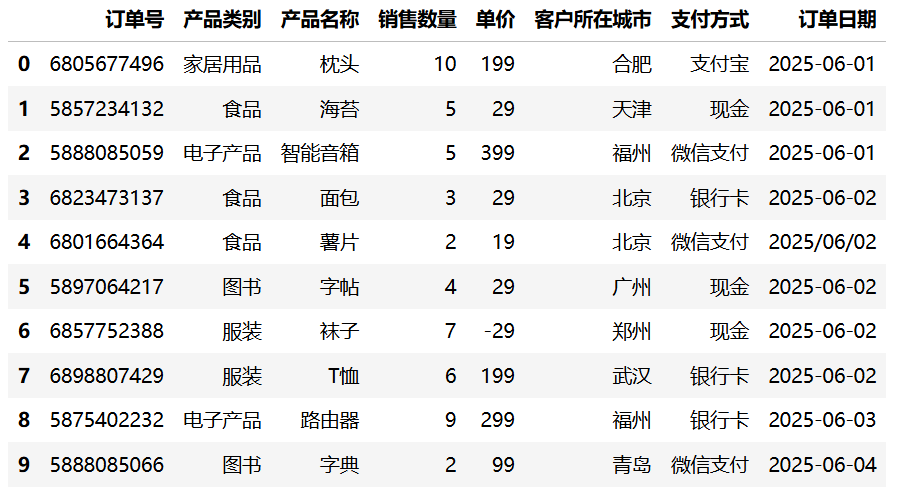
相关信息
ffill() 是 fillna(method='ffill') 的简写形式,意为 "forward fill"。
3. 向后填充(bfill)
使用后一个非缺失值填充当前的缺失值。
import pandas as pd
df = pd.read_csv("data/sales.csv")
df = df.head(10)
df.bfill()运行结果:
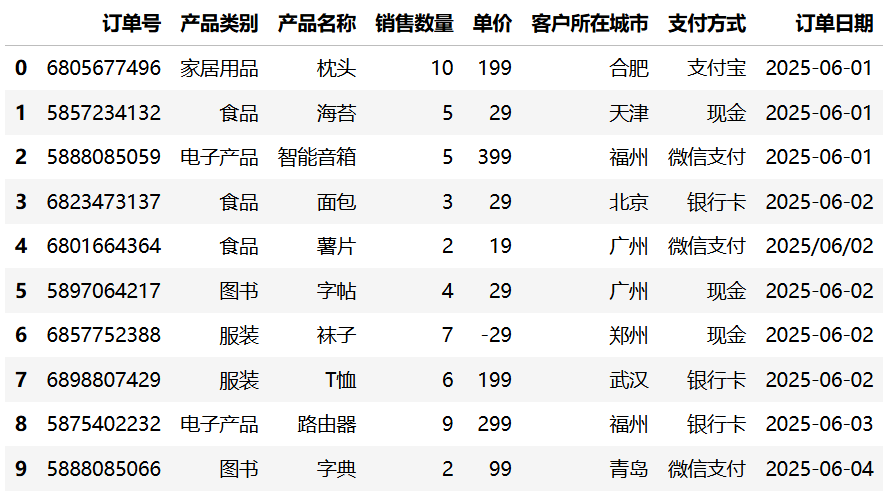
相关信息
bfill() 是 fillna(method='bfill') 的简写形式,意为 "backward fill"。
8.2 重复值处理
数据集中可能存在完全重复或关键字段重复的记录,Pandas 提供了 duplicated() 和 drop_duplicates() 方法来检测和处理这些重复数据。
8.2.1 检测重复值(全列匹配)
使用 duplicated() 方法可以检测 DataFrame 中是否有完全重复的行。默认情况下,它会比较所有列的值。
import pandas as pd
df = pd.read_csv("data/sales.csv")
pd.set_option("display.max_rows", None)
df.duplicated()运行结果:

相关信息
返回的 Series 中,True 表示该行与之前的某一行完全相同,False 表示是首次出现。
8.2.2 检测重复值(指定列匹配)
如果只关心某些关键列(如"订单号")是否重复,可以使用 subset 参数指定列名。
import pandas as pd
df = pd.read_csv("data/sales.csv")
pd.set_option("display.max_rows", None)
df.duplicated(subset=["订单号"])运行结果:

提示
subset 参数可以接受单个列名或列名列表,例如 subset=["订单号", "产品名称"]。
8.2.3 删除重复值
使用 drop_duplicates() 方法可以删除重复的行,保留其中一条记录。
常用参数
subset:指定用于判断重复的列,默认为所有列keep:保留策略'first':保留第一次出现的记录(默认)'last':保留最后一次出现的记录False:删除所有重复的记录(不保留任何一条)
inplace:是否原地修改,默认为 False
import pandas as pd
df = pd.read_csv("data/sales.csv")
pd.set_option("display.max_rows", None)
df.drop_duplicates(subset=["订单号"], keep="last")运行结果:
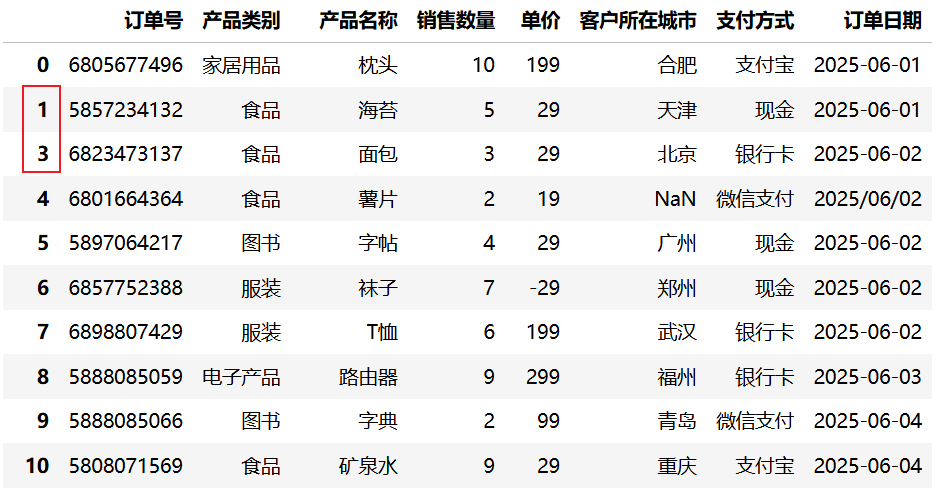
应用场景
在数据合并或采集过程中,可能会产生重复记录。通过 drop_duplicates() 可以确保数据的唯一性。
8.3 异常值处理
异常值是指数据集中明显偏离正常范围的数值(如负数的价格、超出合理范围的年龄等)。处理异常值可以保证数据分析的准确性。
8.3.1 查看异常值
通过条件筛选可以找出符合异常定义的数据。以下示例检测"单价"为负数的异常记录:
import pandas as pd
df = pd.read_csv("data/sales.csv")
pd.set_option("display.max_rows", None)
df[df["单价"] < 0]运行结果:

说明
实际业务中,异常值的定义需要根据具体场景确定,例如可以通过统计学方法(如 3σ 原则、箱线图)来识别。
8.3.2 删除异常值
如果异常值是错误数据且无法修复,可以直接将其从数据集中删除。
import pandas as pd
df = pd.read_csv("data/sales.csv")
pd.set_option("display.max_rows", None)
df_cleaned = df.drop(df[df["单价"] < 0].index)
df_cleaned运行结果:
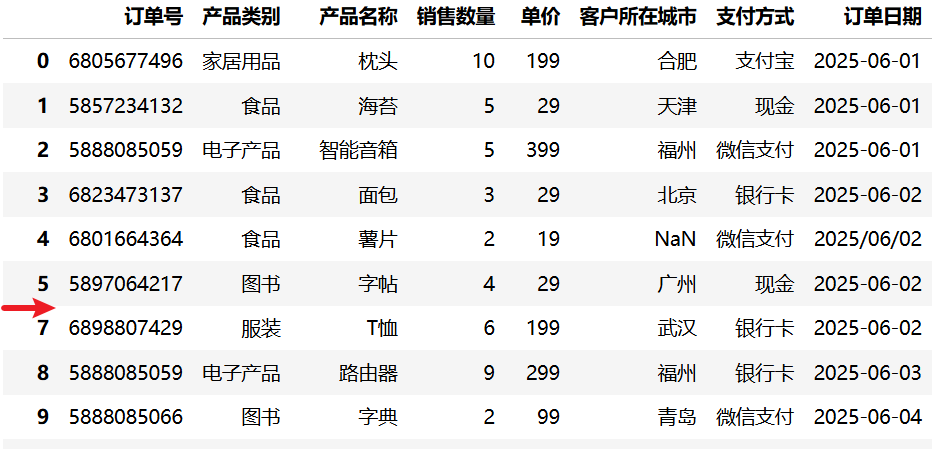
提示
drop() 方法默认返回一个新的 DataFrame,原数据不会被修改。如果需要原地修改,可以设置 inplace=True。
8.3.3 修复异常值
如果异常值是由于数据采集错误导致的(如符号错误),可以尝试进行修复而不是直接删除。以下示例将"单价"列的所有负数取绝对值:
import pandas as pd
df = pd.read_csv("data/sales.csv")
pd.set_option("display.max_rows", None)
df["单价"] = df["单价"].abs()运行结果:
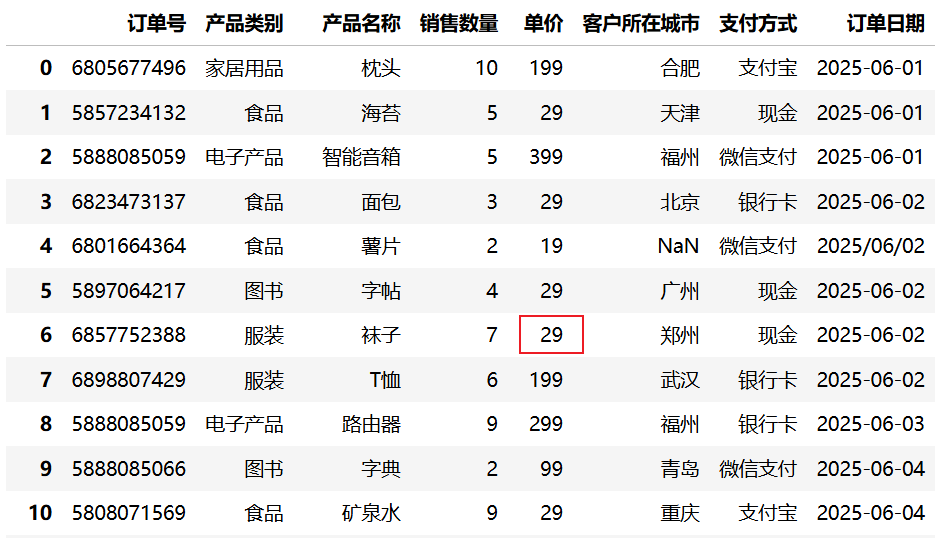
应用场景
- 取绝对值:适用于符号错误的情况
- 替换为均值/中位数:适用于随机误差导致的异常
- 替换为边界值:适用于超出合理范围但方向正确的情况
8.4 数据格式处理
在数据采集或导入过程中,经常会遇到日期格式不统一、字符串包含多余空格等问题。Pandas 提供了强大的字符串处理方法(.str 访问器)来清洗和规范化数据格式。
8.4.1 替换字符串内容
使用 str.replace() 方法可以批量替换列中的特定字符。以下示例将"订单日期"列中的斜杠 / 统一替换为横杠 -,以符合标准的日期格式:
import pandas as pd
df = pd.read_csv("data/sales.csv")
pd.set_option("display.max_rows", None)
# 将日期格式从 "2023/01/01" 转换为 "2023-01-01"
df["订单日期"] = df["订单日期"].str.replace("/", "-")提示
str.replace() 支持正则表达式。如果需要更复杂的替换逻辑,可以传入正则模式。
8.4.2 去除首尾空格
如果数据中存在多余的空格,可以使用 str.strip() 方法进行清理。
import pandas as pd
df = pd.read_csv("data/sales.csv")
# 去除"产品名称"列中每个字符串的首尾空格
df["产品名称"] = df["产品名称"].str.strip()常用方法
str.strip():去除首尾空格str.lstrip():去除左侧空格str.rstrip():去除右侧空格
8.4.3 转换数据类型
清洗完格式后,通常需要将列转换为正确的数据类型,以便进行后续的统计或计算。
import pandas as pd
df = pd.read_csv("data/sales.csv")
# 将"订单日期"列转换为 datetime 类型
df["订单日期"] = pd.to_datetime(df["订单日期"])
# 查看转换后的数据类型
df.dtypes说明
使用 pd.to_datetime() 可以将字符串格式的日期转换为 Pandas 的 datetime64 类型,从而支持按年、月、日进行筛选和聚合分析。
9.数据排序与分组
在进行数据排序时,有两种排序方式,分别是:升序和降序。而基于Pandas进行数据排序时,可以按照多个列进行排序的。
9.1 数据排序
使用 sort_values() 方法可以根据一列或多列的值对 DataFrame 进行排序。
常用参数
by:指定用于排序的列名(字符串)或列名列表ascending:排序顺序,True为升序(默认),False为降序。如果是多列排序,可以传入布尔值列表inplace:是否原地修改,默认为Falsena_position:缺失值的位置,'last'(默认)或'first'
9.1.1 单列降序排序
以下示例根据"销售数量"列进行降序排列,查看销量最高的记录:
import pandas as pd
# 仅读取前10行用于演示
df = pd.read_csv("data/sales.csv", nrows=10)
# 根据销售数量倒序排序
df.sort_values("销售数量", ascending=False)运行结果:
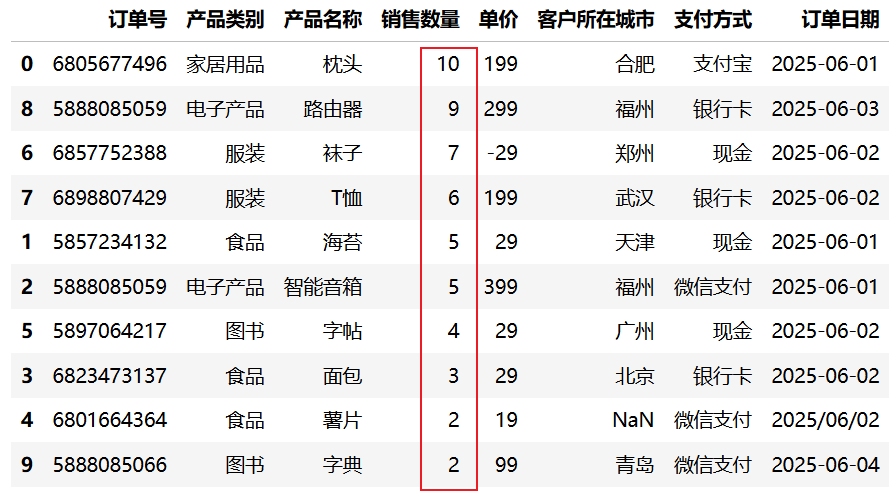
9.1.2 单列升序排序
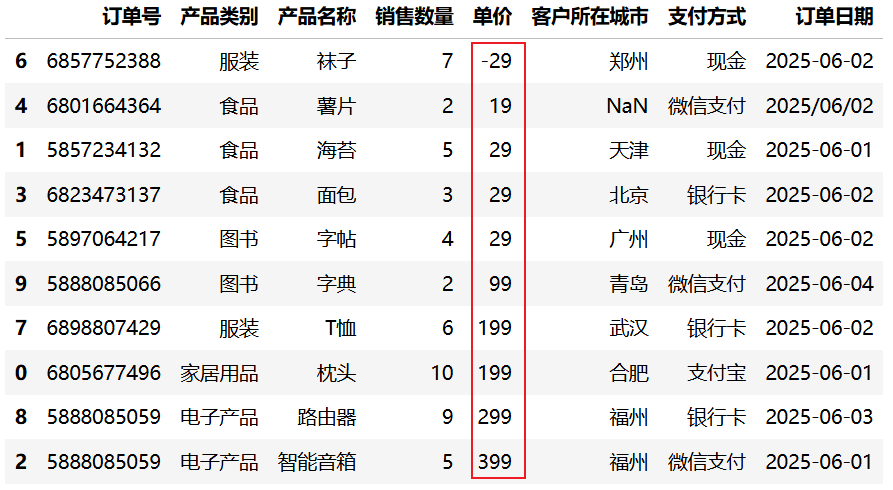
以下示例根据"单价"列进行升序排列,查看价格最低的商品:
import pandas as pd
df = pd.read_csv("data/sales.csv", nrows=10)
# 根据单价升序排序
df.sort_values("单价")运行结果:
9.1.3 多列组合排序
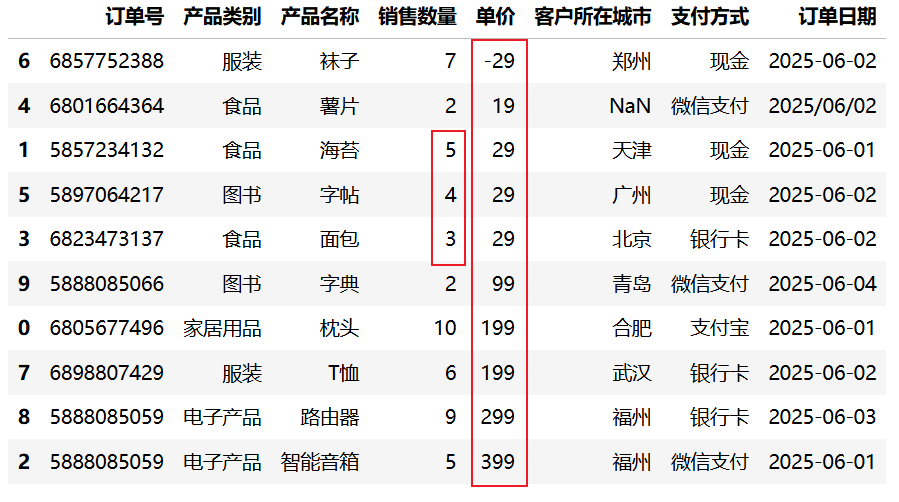
当第一列的值相同时,可以根据第二列进行二次排序。以下示例先按"单价"升序,单价相同时再按"销售数量"降序:
import pandas as pd
df = pd.read_csv("data/sales.csv", nrows=10)
# 根据单价升序排序,价格相同再根据销售数量倒序排序
df.sort_values(["单价", "销售数量"], ascending=[True, False])运行结果:
说明
- 如果
ascending是单个布尔值(如True),它将应用于所有指定的列。 - 如果
ascending是列表,其长度必须与by参数的列数一致,否则会抛出ValueError。
9.2 数据分组
使用 groupby() 方法可以将数据按照一个或多个列进行分组,然后对每个组应用聚合函数(如求和、计数、均值等),从而发现数据的内在规律。
9.2.1 分组计数
统计每个产品类别下的订单数量:
import pandas as pd
df = pd.read_csv("data/sales.csv", nrows=20)
# 根据产品类别分组,统计各个类别的订单数量
df.groupby("产品类别")["订单号"].count()运行结果:
产品类别
图书 5
家居用品 3
服装 3
电子产品 4
食品 5
Name: 订单号, dtype: int649.2.2 分组求和
计算每个产品类别的销售数量总和:
import pandas as pd
df = pd.read_csv("data/sales.csv", nrows=20)
# 根据产品类别分组,统计各个类别的销售数量之和
df.groupby("产品类别")["销售数量"].sum()运行结果:
产品类别
图书 25
家居用品 26
服装 23
电子产品 27
食品 21
Name: 销售数量, dtype: int649.2.3 分组计算衍生指标
先计算每条记录的销售金额,再按类别统计总金额:
import pandas as pd
df = pd.read_csv("data/sales.csv", nrows=20)
# 根据产品类别分组,统计各个类别的销售金额之和
df["销售金额"] = df["单价"] * df["销售数量"]
df.groupby("产品类别")["销售金额"].sum()运行结果:
产品类别
图书 1115
家居用品 4274
服装 4981
电子产品 6943
食品 689
Name: 销售金额, dtype: int649.2.4 分组求最小值
import pandas as pd
df = pd.read_csv("data/sales.csv", nrows=20)
# 根据产品类别分组,统计各个类别的最低商品单价
df.groupby("产品类别")["单价"].min()运行结果:
产品类别
图书 29
家居用品 49
服装 -29
电子产品 89
食品 19
Name: 单价, dtype: int64说明
结果中出现了负数(-29),这通常是数据异常,需要在分析前进行清洗。
9.2.5 分组求最大值
查找每个产品类别中的最高单价:
import pandas as pd
df = pd.read_csv("data/sales.csv", nrows=20)
# 根据产品类别分组,统计各个类别的最高商品单价
df.groupby("产品类别")["单价"].max()运行结果:
产品类别
图书 99
家居用品 199
服装 399
电子产品 399
食品 79
Name: 单价, dtype: int649.2.6 多指标聚合(单列)
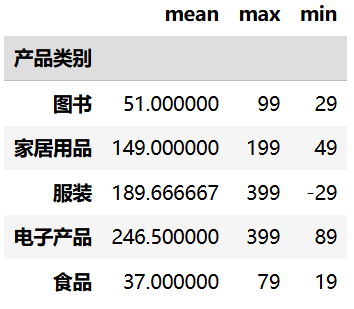
使用 agg() 方法可以同时对同一列应用多个聚合函数:
import pandas as pd
df = pd.read_csv("data/sales.csv", nrows=20)
# 根据产品类别分组,统计各个类别的平均单价、最高单价、最低单价
df.groupby("产品类别")["单价"].agg(["mean", "max", "min"])
df.groupby("产品类别").agg({"单价": ["mean", "max", "min"]})运行结果:
9.2.7 多指标聚合(多列)
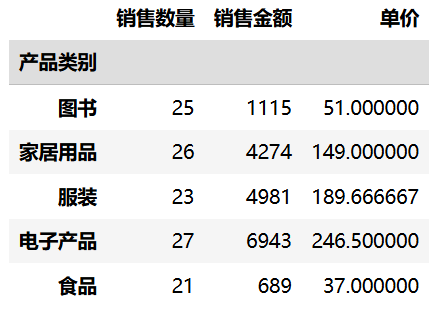
可以对不同的列应用不同的聚合函数,实现复杂的统计分析:
import pandas as pd
df = pd.read_csv("data/sales.csv", nrows=20)
# 根据产品类别分组,统计各个类别的商品的销售数量之和,销售金额之和,平均单价
df.groupby("产品类别").agg({"销售数量": "sum", "销售金额": "sum", "单价": "mean"})运行结果:
提示
agg() 方法非常强大,支持传入字典来为不同列指定不同的聚合逻辑,是数据分析中最常用的工具之一。